
Аппаратное ускорение AI вычислений

Реально достигнутая производительность при утилизации ресурсов FPGA по LUT в 75% (FP24DW)
Задержка от входа до выхода на сети LSTM на частоте 550 МГц
При операциях в нашем проприетарном формате FloatPoint24DW

Локальные вычисления

Вычисления на облачных серверах

СФ-блоки для интеграции в FPGA/ASIC

Тем субботним холодным утром несколько инженеров решили объединить свои усилия на стыке нескольких областей, в числе которых проектирование цифровых схем (FPGA, ASIC), опыт в ЦОС и нейросетях и жгучее желание сделать продукт, превосходящий существующие решения на базе HLS-инструментов.
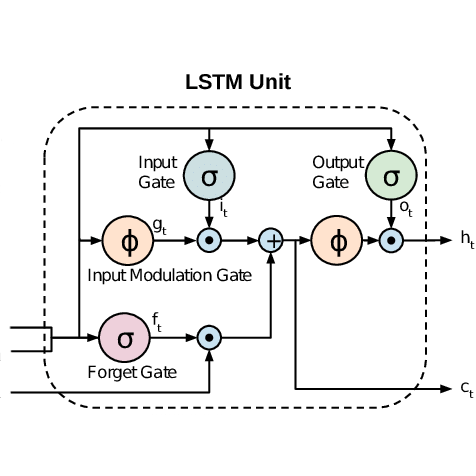
Наша пилотный проект: реализация рекуррентной нейронной сети. В рамках этого пилота была разработана библиотека вычислений в формате представления чисел с плавающей точкой FP24DW, оптимизированная под семейство FPGA Xilinx Ultrascale+. Данное решение для сетей LSTM на текущий момент превосходит существующие state-of-the-art реализации.
Опыт работы с заказчиками показал, что часто используется комбинация из RNN и свёрточной нейросети. Для того чтобы сделать наше решение с CNN коммерчески доступным, в данный момент развиваем средства моделирования и оценки сетей при конфигурируемом квантовании каждого слоя.

Поняв запросы индустрии и ИИ-инженеров, которые наравне с высокой плотностью вычислительной мощности и энергоэффективностью, ценят скорость разработки и удобство инструмента, мы решили обеспечить продукту максимальную доступность, понизив порог входа. В первую очередь мы нацелены на поддержку моделей нейронных сетей в форматах ONNX и PyTorch.